Esse post é uma pesquisa que fiz na graduação como membro do Ganesh-ICMC. Muito do que fiz lá dentro acredito que pode ser útil para mais pessoas e eu queria transmitir esse conhecimento por meio de publicações nesse blog.
Para entender a publicação é interessante ter noções de arquitetura e organização de computadores e sistemas operacionais.


Logos do Meltdown e do Spectre – por Natascha Eibl, Licença CC0
Meltdown e Spectre são vulnerabilidades publicadas em 2018 que afetam processadores modernos. Em particular a pesquisa inicial testou dispositivos da Intel, AMD e ARM, sendo o Meltdown presente em quase todo processador da Intel na data de descoberta e o Spectre presente em CPUs das três empresas.
O que faz dessas vulnerabilidades interessantes é que elas exploram características do hardware e não do software. Em particular, elas utilizam de uma otimização chamada execução especulativa para vazar dados através da memória cache do processador. Essa otimização é importante para a performance e removê-la pode ser inviável quando alto desempenho é relevante.
Além disso, é bom observar que uma correção em hardware envolveria trocar fisicamente os processadores, o que seria bastante custoso de fazer em escala. Porém, apesar do Hardware ser vulnerável, existem correções em software que mitigam os problemas.
Um outro ponto que acho curioso é que os pesquisadores criaram logo e nome para a vulnerabilidade, e não utilizaram apenas os números das CVEs. Outras vulnerabilidades de execução especulativa também fizeram isso, como: Foreshadow, ZombieLoad e MDS. A página do wargame io.netgarage tem uma coleção de logos para vulnerabilidades.
Em uma visão geral, Meltdown e Spectre foram apenas as primeiras vulnerabilidades a serem descobertas. Uma busca por CVEs termo “Speculative Execution” traz 32 resultados, o que indica que esses ataques ainda são temas de pesquisa relevantes.
É possível verificar se seu processador é afetado por alguma vulnerabilidade de execução especulativa através dessa ferramenta (executar como superusuário).
Execução Especulativa
O princípio básico de funcionamento das vulnerabilidades é a execução especulativa. Esse efeito ocorre quando o processador realiza alguma instrução sem realmente ter certeza de que ela de fato é necessária.
Caso a instrução não seja realmente seja executada no futuro, o resultado é descartado, mas caso seja, ela foi realizada de forma adiantada e tem-se ganho de performance. O processo de confirmar uma instrução executada especulativamente se chama retirement.
Um exemplo de como isso pode acontecer é durante um desvio condicional, como a seguir:
variavel = a+b;
if (variavel == 42) {
# instruções_dentro_do_if
}
# instruções_fora_do_if
Durante a execução do código acima, é necessário decidir se o código vai saltar para instruções_dentro_do_if ou para instruções_fora_do_if.
Devido ao pipeline de instruções do processador, a comparação dentro do if pode aparecer antes de que o valor de variavel seja realmente calculado. No pipeline a instrução seguinte começa antes de que a anterior tenha realmente finalizado.
Para tratar esse if, a solução mais direta seria aguardar o resultado ser calculado e continuar a instrução em seguida, formando uma bolha no pipeline. Porém a bolha é um tempo em que o processador poderia estar realizando uma operação, mas não o faz, o que é negativo para a performance.
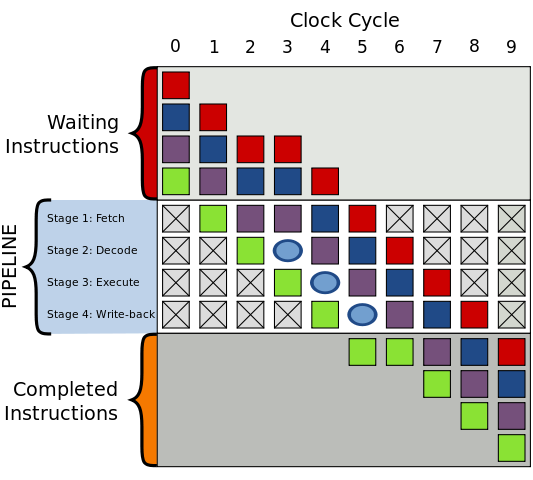
Portanto é interessante para o processador tentar “adivinhar” qual o caminho que o programa segue dentro do if, livrando-se de um ciclo de clock em espera. Com isso a performance é ideal quando adivinha-se corretamente e o efeito da bolha só aparece quando o processador adivinha incorretamente.
Ataques de Cache
Tendo em mente essa característica de o processador executar instruções especulativamente, pode-se perguntar qual a relevância dela. Se a execução da instrução é descartada quando a predição é incorreta, que efeito ela tem?
Em termos de resultados das operações, realmente não há nenhuma mudança, mas existe um efeito colateral no carregamento da memória cache do processador. Uma instrução especulativa é capaz de trazer um dado da memória RAM para a memória cache, que tem menor latência.
Daí tem-se um side-channel em que é possível observar se uma memória foi ou não acessada a partir do seu tempo de acesso. O tempo de acesso da memória cache L1, a mais rápida, é significativamente menor do que o acesso a RAM. Essa página traz uma visualização interessante para latência de memória em diferentes operações.
Essa diferença de tempo é grande o suficiente para ser observada na prática, mas é importante utilizar uma medida de tempo com alta resolução porque queremos medir um tempo tão curto quanto uma única instrução. Chamar uma função como a time da libc seria inviável devido ao tempo da chamada de função.
Para tanto pode-se utilizar o contador de clock do processador por inline assembly com a instrução RDTSC. Para garantir que uma posição da memória não está carregada no cache existe também a instrução CLFLUSH. O código C a seguir, inspirado na PoC do Meltdown, demonstra essa medida de tempo.
#include<stdio.h>
#include<stdint.h>
#include<math.h>
static inline void maccess(void *p) {
asm volatile("movl (%0), %%eax\n" : : "c"(p) : "eax");
}
static inline void flush(void *p) {
asm volatile("clflush 0(%0)\n" : : "c"(p) : "eax");
}
static inline uint64_t rdtsc() {
uint64_t a = 0, d = 0;
asm volatile("mfence");
asm volatile("rdtsc" : "=A"(a));
a = (d <<; 32) | a;
asm volatile("mfence");
return a;
}
float mean(int* v, int n) {
long long sum = 0;
for(int i=0; i<n;i++)
sum += v[i];
return sum/(float)(n);
}
float stdev(int* v, int n, int mean) {
long long sum = 0;
for(int i=0; i<n;i++){
int sq_dif = v[i]-mean;
sum += sq_dif*sq_dif;
}
return sqrt(sum/(float)(n));
}
#define N_TRIES 10000
int main(int argc, char * argv[]){
char buffer[4096];
int cache_times[N_TRIES];
int ram_times[N_TRIES];
int start, end;
for(int i=0; i<N_TRIES; i++){
// cached access
maccess(buffer);
start = rdtsc();
maccess(buffer);
end = rdtsc();
cache_times[i] = end-start;
// uncached access
flush(buffer);
start = rdtsc();
maccess(buffer);
end = rdtsc();
ram_times[i] = end-start;
}
float time_mean = mean(cache_times, N_TRIES);
float time_stdev = stdev(cache_times, N_TRIES, time_mean);
printf("Cached time = %.2f +- %.2f\n", time_mean, time_stdev);
time_mean = mean(ram_times, N_TRIES);
time_stdev = stdev(ram_times, N_TRIES, time_mean);
printf("Uncached time = %.2f +- %.2f\n", time_mean, time_stdev);
return 0;
}
No meu dispositivo os tempos foram:
Cached time = 97.22 +- 14.46
Uncached time = 309.71 +- 82.22Observa-se então que a instrução RDTSC tem resolução suficiente para distinguir se um acesso a memória ocorre na memória cache ou na memória RAM.
Para ilustrar uma transmissão de dados através dessa característica da memória, o código abaixo envia uma mensagem por meio desse side-channel. Ele lê os caracteres a serem transmitidos da entrada do usuário, transforma seu valor no offset de um buffer e realiza a leitura daquele endereço, carregando ele no cache.
A leitura nesse buffer é realizada a cada 4096 posições porque o cache é organizado em linhas de cache em que posições de memória próximas são carregadas juntas, em pacotes tipicamente com 512-4096 bytes. Essa multiplicação por 4096 garante que cada valor transmitido seja em uma linha de cache diferente.
Paralelamente, um receptor constantemente faz medidas de tempo da leitura ao longo desse buffer e escreve o valor na tela caso o tempo seja de uma leitura no cache, abaixo de THRESHOLD.
#include<pthread.h>
#define CACHE_LINE_SIZE 4096
char buffer[256*CACHE_LINE_SIZE];
const uint64_t THRESHOLD = 200;
void * receiver(void * dummy){
uint64_t start, end;
uint64_t time;
void *addr;
while(1){
for (int i = 1; i < 256; i++){
addr = buffer+(i*CACHE_LINE_SIZE);
start = rdtsc();
maccess(addr);
end = rdtsc();
time = end-start;
flush(addr);
if(time < THRESHOLD){
putchar(i);
}
}
}
}
void sender(){
int input = 0;
while(input != EOF){
input = getchar();
*( buffer+(input*CACHE_LINE_SIZE) ) = 0;
usleep(100);
}
}
int main(){
pthread_t thread;
pthread_create(&thread, NULL, &receiver, NULL);
sleep(1);
sender();
return 0;
}
Observa-se que o receptor consegue receber corretamente maior parte dos caracteres. No meu dispositivo surgiu a seguinte entrada/saída.
rqiwoaufhkdjvbhjkeryncaosjlkcjhnuiryaovicnukljhreiurihjsdklfhdsaioeurw
woaufhkdjvbhjkeryncaojkcjhnuiryaovicnukljhreiurihjdklfhdsaioeurwMeltdown
A vulnerabilidade Meltdown aparece devido a uma outra otimização de hardware chamada execução fora de ordem. Ela aproveita a característica que as CPUs modernas tem arquitetura superescalar, isso é, são capazes de realizar múltiplas instruções simultaneamente. Para tanto as CPUs apresentam múltiplas unidades de execução como mostra a figura abaixo.

A ideia principal da execução fora de ordem é buscar adiante da posição atual do programa se há uma instrução com alguma unidade livre capaz de executar ela. Caso seja possível, a instrução é executada mais cedo para que aquela unidade de execução não fique inativa.
Com isso as instruções podem não ser executadas na ordem que aparecem, mas são executadas a partir do momento em que há recursos disponíveis. O processo de retirement, que confirma a execução dessas instruções executadas especulativamente, ocorre na ordem que as instruções aparecem e serve como reordenação para a ordem correta.
O Meltdown aproveita da execução fora de ordem para executar especulativamente instruções mesmo após uma instrução que resulta em erro, em particular um acesso a memória numa região proibida.
Ele funciona de maneira semelhante ao exemplo da sessão de ataques de cache, mas com o emissor sendo um código que acessa um endereço de memória proibido e envia seu valor pelo side-channel de cache. O código do Meltdown aparece a seguir, conforme a referência [2]:
; rcx = kernel address, rbx = probe array xor rax, rax retry: mov al, byte [rcx] shl rax, 0xc jz retry mov rbx, qword [rbx + rax]
No código, rcx é um endereço de memória com acesso proibido e que se deseja vazar, e rbx é o endereço do buffer em que o receptor realiza a leitura e verifica o tempo gasto.
A instrução xor rax, rax zera o valor do registrador rax, que é usado posteriormente.
A instrução mov al, byte [rcx] realiza a leitura de uma região proibida e causa uma interrupção, mas devido a execução fora de ordem, as instruções seguintes podem executar especulativamente. Tipicamente o sistema operacional encerra o processo após um acesso inválido, mas é possível evitar isso tratando ou suprimindo essa interrupção.
A instrução shl rax, 0xc é uma multiplicação do valor vazado por 4096 para evitar acesso na mesma linha de cache.
A instrução jz retry é um tratamento de erro em que caso o acesso da memória falhe, o valor lido é zero. Se isso acontecer o exploit tenta realizar a leitura novamente.
Por fim, a instrução mov rbx, qword [rbx + rax] realiza uma leitura no buffer em que o receptor observa, transmitindo assim o dado lido.
O resultado é que qualquer região de memória pode ser lido, sem qualquer limitação do sistema operacional. Um ponto importante é que, na época que a vulnerabilidade foi descoberta, toda a memória RAM estava disponível no espaço de endereçamento do kernel nos principais sistemas operacionais.
Com o Meltdown em condições ideais, os pesquisadores conseguiram uma velocidade de transmissão de 582 KB/s com uma taxa de erro mínima de apenas 30 erros a cada milhão de leituras! Exemplos do uso do Meltdown para vazar dados aparecem aqui.
Spectre
O Spectre é, na verdade, duas vulnerabilidades diferentes que atacam a mesma otimização de hardware, o preditor de ramo, e difere do Meltdown no sentido que é direcionada a um processo alvo.
A primeira variante é chamada de Bounds Check Bypass (BCB) e a segunda de Branch Target Injection (BTI). A primeira vale para desvios condicionais, como num if ou num while, e a segunda para desvios indiretos, como saltar para um ponteiro de código ou um retorno de função.
O preditor de ramo é uma estratégia que visa otimizar o tempo de execução quando o programa deve saltar para uma região ainda desconhecida. O processador tenta adivinhar qual o caminho tomado e executa-o especulativamente. Daí novamente tem-se um ganho de performance se a predição for correta e descarta-se o resultado se ela for incorreta.
A Variante 1 do Spectre (BCB) ataca desvios condicionais, por exemplo a decisão de “entrar” ou não dentro de um if. Nela, uma escolha incorreta do preditor ramo realiza uma execução especulativa que pode vazar dados. O código abaixo, que aparece em [3], ilustra uma sessão de código vulnerável.
if (x < array1_size)
y = array2[array1[x] * 4096]
Nele há uma verificação de que x é uma posição válida do array1, e caso verdadeiro ela realiza uma leitura em array2 de forma semelhante com o exemplo mostrado na sessão de ataque de cache. Essa leitura, conforme discutido, tem um efeito colateral no cache e pode ser observada mesmo caso a execução seja apenas especulativa.
O problema desse if é que, caso x seja um valor maior do que o permitido e o preditor de ramo incorretamente entre dentro do if, a sessão de código é executada especulativamente e vaza um dado. Essa situação pode aparecer se array1_size estiver fora do cache, mas as outras variáveis estiverem presentes. A figura abaixo ilustra as possibilidades de previsão.

Já a Variante 2 do Spectre (BTI) ataca desvios indiretos, como a instruções jmp eax e ret. Nesses casos o processador tem tabelas com os últimos endereços em que o salto acontece, o Branch Target Buffer (BTB) e o Return Stack Buffer (RSB), exclusivo para a instrução ret.
O ataque consiste em injetar nessas tabelas o endereço de uma sessão de código capaz de vazar dados por um side-channel de cache, o que seria um gadget semelhante ao que aparece no Return Oriented Programming (ROP). Assim, o programa atacado executa especulativamente esse gadget injetado e pode vazar algum dado.
Em ambas as variantes, os preditores de ramo podem ser treinados por um segundo processo compartilhando o mesmo núcleo da CPU. Ou seja, pode-se criar uma thread que realiza um desvio semelhante ao que existe no processo alvo múltiplas vezes para “treinar” o processador e forçar o alvo a realizar uma predição incorreta.
Por fim, pode-se observar que a exploração do Spectre é bem mais complexa do que a do Meltdown, visto que ela envolve encontrar padrões vulneráveis no programa que se deseja atacar. Porém ela é bastante comum e ataca um recurso de otimização que aparece em diversos tipos de processadores.
Discussão
As vulnerabilidades Meltdown e Spectre atualmente já foram tratadas, com correções em software e em hardware que mitigam seus efeitos, e não devem ser exploráveis em um sistema atualizado. Porém elas são ótimas para ilustrar como é possível o hardware ser vulnerável e podem ser úteis para entender melhor como um processador moderno funciona.
Além disso, o problema da execução especulativa é muito maior do que apenas as primeiras vulnerabilidades descobertas. Ao longo dos anos foram encontradas várias outras vulnerabilidades do mesmo tipo.
Referências
[1] https://spectreattack.com/
[2] Lipp, Moritz, et al. “Meltdown: Reading Kernel Memory from User Space.” 27th USENIX Security Symposium (USENIX Security 18), 2018.
[3] Kocher, Paul, et al. “Spectre Attacks: Exploiting Speculative Execution.” 40th IEEE Symposium on Security and Privacy (S&P’19), 2019.
[4] https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html
[5] Prout, Andrew, et al. “Measuring the Impact of Spectre and Meltdown.” 2018 IEEE High Performance Extreme Computing Conference (HPEC), 2018, pp. 1–5, doi:10.1109/HPEC.2018.8547554.
[6] Yarom, Yuval, and Katrina Falkner. “FLUSH+RELOAD: A High Resolution, Low Noise, L3 Cache Side-Channel Attack.” 23rd USENIX Security Symposium (USENIX Security 14), USENIX Association, 2014, pp. 719–32, https://www.usenix.org/conference/usenixsecurity14/technical-sessions/presentation/yarom.
[7] https://www.felixcloutier.com/x86/rdtsc
[8] https://gist.github.com/hellerbarde/2843375
[9] https://github.com/IAIK/meltdown