This post comes from a research I did as an undergraduate and member of Ganesh-ICMC. I believe much of the stuff I did there could be useful to more people, so I’d like to share this knowledge through publications in this blog
To understand this post it is good to have notions of computer architecture and organization and of operating systems.


Meltdown and Spectre logos – by Natascha Eibl, CC0 License
Meltdown and Spectre are vulnerabilities in modern processor that were published in 2018. In particular, the initial research tested devices from Intel, AMD and ARM, Meltdown being present in almost every Intel processor in the date of discovery and Spectre present in CPUs from all of the three.
What makes these vulnerabilities interesting is that they explore hardware features rather than software. More precisely, they use an optimization called speculative execution to leak data through the processor’s cache memory. This optimization is important to the performance and removing it may infeasible be when high performance is relevant.
More than that, it is nice to remark that a hardware correction would involve to physically exchange the processors, which would be very costly to do in scale. However, even if the Hardware is vulnerable, there are software corrections that mitigate the problems.
Another point that I find curious is that the researches created a logo and a name for the vulnerabilities, instead of just using their CVE numbers. Other speculative execution vulnerabilities also did that, like: Foreshadow, ZombieLoad and MDS. The io.netgarage wargame website has a collection of vulnerabilities’ logos.
At a broad view, Meltdown and Spectre were only the first vulnerabilities to be discovered. A search for CVEs with the term “Speculative Execution” brings 32 results, which points that these attacks are still relevant research themes.
It is possible to verify if your processor is affected by some speculative execution through this tool (run as root).
Speculative Execution
The basic principle of the vulnerabilities is the speculative execution. This effect happens when the processor runs an instruction without really being sure if it is necessary.
If the instruction ended up not really being executed in the future, the result is discarded, but if it was, the instruction would have been run earlier than necessary and there is a performance gain. The process of confirming a speculatively executed instruction is called “retirement”.
An exemple of how this may happen is at a conditional branch, like as follows:
variable = a+b;
if (variable == 42) {
# instructions_inside_if
}
# instructions_outside_if
During the execution of the code above, it is necessary to choose if the code will jump to instructions_inside_if or to instructions_outside_if.
Due to the processor’s instruction pipeline, the comparison inside the if may appear before the value of variable is actually calculated. In the instruction pipeline the next instruction starts before the previous has fully finished.
To deal with this if, the most immediate solution would be to wait for the calculation of the result and to continue the instructions after that, which would make a pipeline bubble. However a bubble is a time in which a processor could be running an operation, but does not, which is bad for performance.
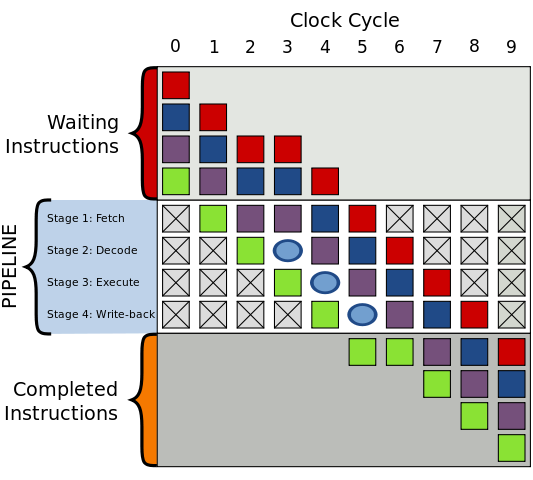
Therefore, it is good to the processor to try to “guess” which path the program would take because of the if, avoiding an idle clock cycle. Because of this, the performance is ideal when the processor correctly guesses the path and the bubble only exists if the processor guesses incorrectly.
Cache Attacks
Keeping on mind this characteristic that the processor runs instructions speculatively, one may ask how this is relevant. If the instruction execution is discarded when the prediction is wrong, what effect does it have?
In terms of the operations’ result, there really is no difference, but there is a side effect of loading data to the cache memory of the processor. A speculative instruction is able to bring data from the RAM memory to the cache memory, that has lower latency.
Because of this, there is a side-channel in which it is possible to determine if a memory was accessed or not based in it’s loading time. The access time of the L1 cache memory, the fastest of them, is significantly lower than the RAM access time. This page has a nice chart for memory latency of different operations.
This time difference is large enough that it can be seen in practice, but it is important to use a high resolution time measurement because we want to measure a time as short as an instruction. Calling a function like time, from libc, would be unfeasible because of the time overhead of the function call.
To do this we can use the processor’s clock counter through inline assembly, using the RDTSC instruction. To guarantee that a memory position is not loaded to the cache there is also the CLFLUSH instruction. The following C code, based in Meltdown’s PoC, shows this time measurement.
#include<stdio.h>
#include<stdint.h>
#include<math.h>
static inline void maccess(void *p) {
asm volatile("movl (%0), %%eax\n" : : "c"(p) : "eax");
}
static inline void flush(void *p) {
asm volatile("clflush 0(%0)\n" : : "c"(p) : "eax");
}
static inline uint64_t rdtsc() {
uint64_t a = 0, d = 0;
asm volatile("mfence");
asm volatile("rdtsc" : "=A"(a));
a = (d <<; 32) | a;
asm volatile("mfence");
return a;
}
float mean(int* v, int n) {
long long sum = 0;
for(int i=0; i<n;i++)
sum += v[i];
return sum/(float)(n);
}
float stdev(int* v, int n, int mean) {
long long sum = 0;
for(int i=0; i<n;i++){
int sq_dif = v[i]-mean;
sum += sq_dif*sq_dif;
}
return sqrt(sum/(float)(n));
}
#define N_TRIES 10000
int main(int argc, char * argv[]){
char buffer[4096];
int cache_times[N_TRIES];
int ram_times[N_TRIES];
int start, end;
for(int i=0; i<N_TRIES; i++){
// cached access
maccess(buffer);
start = rdtsc();
maccess(buffer);
end = rdtsc();
cache_times[i] = end-start;
// uncached access
flush(buffer);
start = rdtsc();
maccess(buffer);
end = rdtsc();
ram_times[i] = end-start;
}
float time_mean = mean(cache_times, N_TRIES);
float time_stdev = stdev(cache_times, N_TRIES, time_mean);
printf("Cached time = %.2f +- %.2f\n", time_mean, time_stdev);
time_mean = mean(ram_times, N_TRIES);
time_stdev = stdev(ram_times, N_TRIES, time_mean);
printf("Uncached time = %.2f +- %.2f\n", time_mean, time_stdev);
return 0;
}
On my device, the times were:
Cached time = 97.22 +- 14.46
Uncached time = 309.71 +- 82.22So we can see that the RDTSC instruction has high enough resolution to differentiate if a memory access is made in cache or in RAM.
To illustrate a data transmission through this characteristic of memory, the code below sends a message using this side-channel. It reads the characters to be sent from user input, transforms their value to a offset of a buffer and reads that address, loading it to the cache.
The memory read at this buffer is made every 4096 positions because the cache is organized with cache lines, in which close together memory positions are loaded together, in groups of usually 512-4096 bytes. This multiplication by 4096 guarantees that every transmitted value falls in a different cache line.
Parallel to that, a receptor constantly makes time measurements along this buffer, and writes the read value in the screen if the time corresponds to a cache memory loading time, that is, below THRESHOLD.
#include<pthread.h>
#define CACHE_LINE_SIZE 4096
char buffer[256*CACHE_LINE_SIZE];
const uint64_t THRESHOLD = 200;
void * receiver(void * dummy){
uint64_t start, end;
uint64_t time;
void *addr;
while(1){
for (int i = 1; i < 256; i++){
addr = buffer+(i*CACHE_LINE_SIZE);
start = rdtsc();
maccess(addr);
end = rdtsc();
time = end-start;
flush(addr);
if(time < THRESHOLD){
putchar(i);
}
}
}
}
void sender(){
int input = 0;
while(input != EOF){
input = getchar();
*( buffer+(input*CACHE_LINE_SIZE) ) = 0;
usleep(100);
}
}
int main(){
pthread_t thread;
pthread_create(&thread, NULL, &receiver, NULL);
sleep(1);
sender();
return 0;
}
We can see that the receptor is able to receive correctly most of the characters. In my device I was able to get the following input/output:
rqiwoaufhkdjvbhjkeryncaosjlkcjhnuiryaovicnukljhreiurihjsdklfhdsaioeurw
woaufhkdjvbhjkeryncaojkcjhnuiryaovicnukljhreiurihjdklfhdsaioeurwMeltdown
The Meltdown vulnerability happens because of another hardware optimization called out-of-order execution. It explores modern CPUs’ supercalar architecture, which means they are able to execute multiple instructions simultaneously. To do that, CPUs have multiple execution units, as shown in the figure below.

The main idea of out-of-order execution is to seek ahead of the current program position for instructions that a free execution unit can execute. If it is possible, the instruction is executed earlier so that the execution unit does not become idle.
Because of this, the instructions may not be executed in the order they appear, they are executed as soon as there are enough resources. The retirement process, that confirms the execution of there speculative instructions, happens in the order that the instructions appear and reorders them to the right order.
Meltdown explores the out-of-order execution to speculatively execute instructions even after an instruction gives an error, in particular a memory access to a unauthorized region.
It works in the same way as the example in the Cache Attacks section, but the emitter is a code that reads an prohibited memory address and sends it’s value through the cache side-channel. The Meltdown code is as follows, as in the reference [2]:
; rcx = kernel address, rbx = probe array xor rax, rax retry: mov al, byte [rcx] shl rax, 0xc jz retry mov rbx, qword [rbx + rax]
In the code, rcx is a unauthorized memory address which we want to leak, and rbx is the address of the buffer which the receptor reads and measures the access time.
The xor rax, rax instructions zeroes the value of the rax registes, which is used later.
The mov al, byte [rcx] instruction reads the unauthorized memory region, which creates an interruption, but because of the out-of-order execution, the next instructions may still execute speculatively. Usually, the operating sistem ends a process after an invalid access, but is possible to avoid this by handling or supressing the interruption.
The shl rax, 0xc instruction is the multiplication of the leaked value by 4096 to avoid a memory access in the same cache line.
The jz retry is an error handling for the case in which the memory access fails and it gives a zero. If that happens, the exploit tries to read the memory again.
Finally, the mov rbx, qword [rbx + rax] instruction makes a read in the buffer which the receiver tracks, transmiting the data.
The result of all of this is that any memory region can be read, without any limiting of the operating system. Another important point is that, when the vulnerability was discovered, the whole RAM memory was available inside the kernel address space in the main operating systems.
At ideal conditions for Meltdown, the researches could get a transmission velocity of 582 KB/s with an minimum error rate of only 30 errors for every million readings! Examples of Meltdown use to leak data can be found here.
Spectre
Spectre is actually two different vulnerabilities that attack the same hardware optimization, the branch predictor, and it is different from Meltdown in the sense that it is directed to a target process.
The first variant is called Bounds Check Bypass (BCB) and the second it Branch Target Injection (BTI). The first attacks conditional branches, as in an if or a while, and the second is for indirect branches, as jumping to a code pointer or a function return.
The branch predictor is a stratategy that seeks to optimize the execution time the program when it has to jump to a still unknown region. The processor tries to guess what path should be taken and executes it speculatively. There is a performance gain if the prediction is correct, and if the prediction is incorrect, the result is discarded.
The Variant 1 of Spectre (BCB) attacks conditional branches, for example, the decision to “enter” an if or not. In this variant, an incorrect choice from the branch predictor makes a speculative execution that may leak data. The code below, from [3], show a vulnerable code section.
if (x < array1_size)
y = array2[array1[x] * 4096]
In the code there is a validation that x is a valid position in array1, and if it is, it makes a memory read at array2 similar to the example shown in the cache attack session. This memory read, as previously discussed, has a side effect in the cache which can be observed even if the execution is only speculative.
The problem of this if, is that if x is bigger than the allowed value and the branch predicor incorrectly jumps inside the if, the code section is speculatively executed and leaks the data. This situation may appear if array1_size is outside the cache, but the other variables are available. The figure below shows the prediction possibilities.

The Variant 2 of Spectre (BTI) attacks indirect branches, like the instructions jmp eax and ret. In these cases the processor has tables with the last used addresses to which the jump goes, the Branch Target Buffer (BTB) and the Return Target Buffer (RSB), which is only for the ret instruction.
The attack consists in injecting adresses of a code section that is able to leak data through a cache side-channel in these tables. These code sections are gadgets similar to what is used for Return Oriented Programming (ROP). With this injection, the attacked program executes speculatively this gadget and may leak data.
In both variants, the branch predictors can be trained by a second process sharing the same CPU core. That is, one can create a thread that does similar branching to what there is in the target process and do that multiple times to “train” the processor. This would force the target to make a wrong prediction.
Finally, we can see that the exploration of Spectre is much more complex than of Meltdown, because it involves finding vulnerable patterns in the target program instead of just freely leaking memory. However it is very common and attacks and optimization resource that appears in many kinds of processors.
Discussion
Nowadays the Meltdown and Spectre vulnerabilities have already been treated, with software and hardware corrections that mitigate their effects, and they shouldn’t be exploitable in an updated system. However they are great to show how it is possible that the hardware is vulnerable and they are useful to understand how a modern processor works.
Also, the problem of speculative execution is way bigger than just these first vulnerabilities to be discovered. Over the years, many vulnerabilities of the same type were found.
References
[1] https://spectreattack.com/
[2] Lipp, Moritz, et al. “Meltdown: Reading Kernel Memory from User Space.” 27th USENIX Security Symposium (USENIX Security 18), 2018.
[3] Kocher, Paul, et al. “Spectre Attacks: Exploiting Speculative Execution.” 40th IEEE Symposium on Security and Privacy (S&P’19), 2019.
[4] https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html
[5] Prout, Andrew, et al. “Measuring the Impact of Spectre and Meltdown.” 2018 IEEE High Performance Extreme Computing Conference (HPEC), 2018, pp. 1–5, doi:10.1109/HPEC.2018.8547554.
[6] Yarom, Yuval, and Katrina Falkner. “FLUSH+RELOAD: A High Resolution, Low Noise, L3 Cache Side-Channel Attack.” 23rd USENIX Security Symposium (USENIX Security 14), USENIX Association, 2014, pp. 719–32, https://www.usenix.org/conference/usenixsecurity14/technical-sessions/presentation/yarom.
[7] https://www.felixcloutier.com/x86/rdtsc
[8] https://gist.github.com/hellerbarde/2843375
[9] https://github.com/IAIK/meltdown
1 Comment
What is up!